Previously, I was a student researcher at the MIT–IBM Watson AI
Lab, pretraining large language models and doing research on vision–language models with Dr. Rameswar Panda, Dr. Rogerio
Feris, and Prof. Yoon Kim. I completed a dual degree
(B.Tech + M.Tech) at IIT Kharagpur, where I worked in the Computer Vision and Intelligence Research Lab under Prof. Abir Das.
In Summer 2021, I worked with Prof. Kate Saenko (Boston
University) and Prof. Trevor Darrell (UC Berkeley) as a
research intern for the DARPA LwLL project.
Research
My research focuses on building multimodal foundation models that perceive, reason, and interact in 3D
environments. I am particularly interested in developing unified representations that bridge geometry, vision,
and language-guided systems that can understand spatial relationships, engage in grounded conversations, and
perform complex reasoning tasks. My work spans 3D tokenization for sequential modeling, conversational visual
understanding, and parameter-efficient adaptation of large models. Ultimately, I aim to advance embodied AI
systems that can robustly interpret and act within real-world environments to benefit society.
News
“Conversational Image Segmentation: Grounding Abstract Concepts with Scalable Supervision (ConverSeg)” accepted at CVPR 2026 (arXiv, project page).
“Aligning Text, Images, and 3D Structure Token-by-Token (Kyvo)” accepted at CVPR 2026 (arXiv, project page).
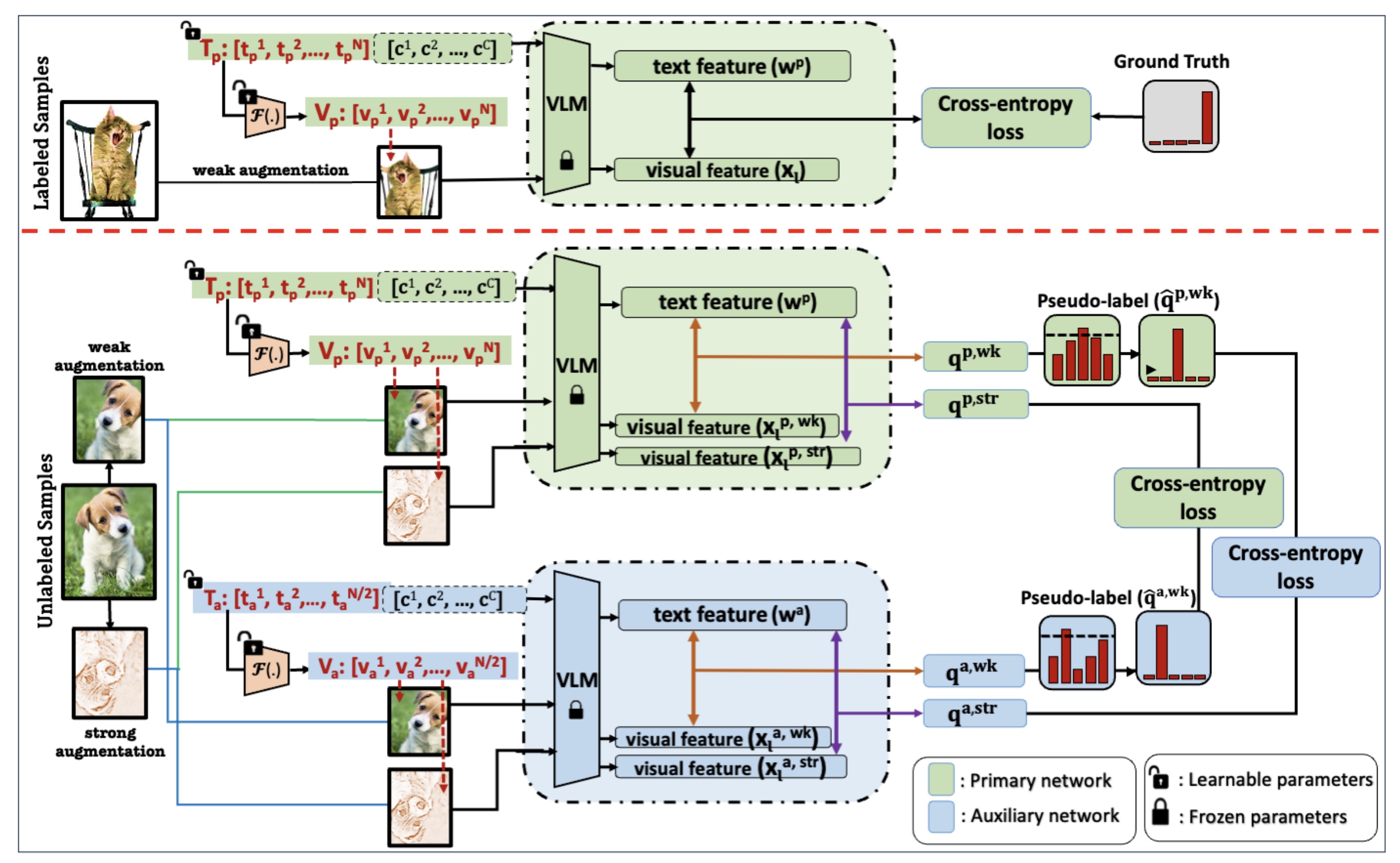
“XPL: A Cross-Model framework for Semi-Supervised Prompt Learning in VLMs” accepted by TMLR.
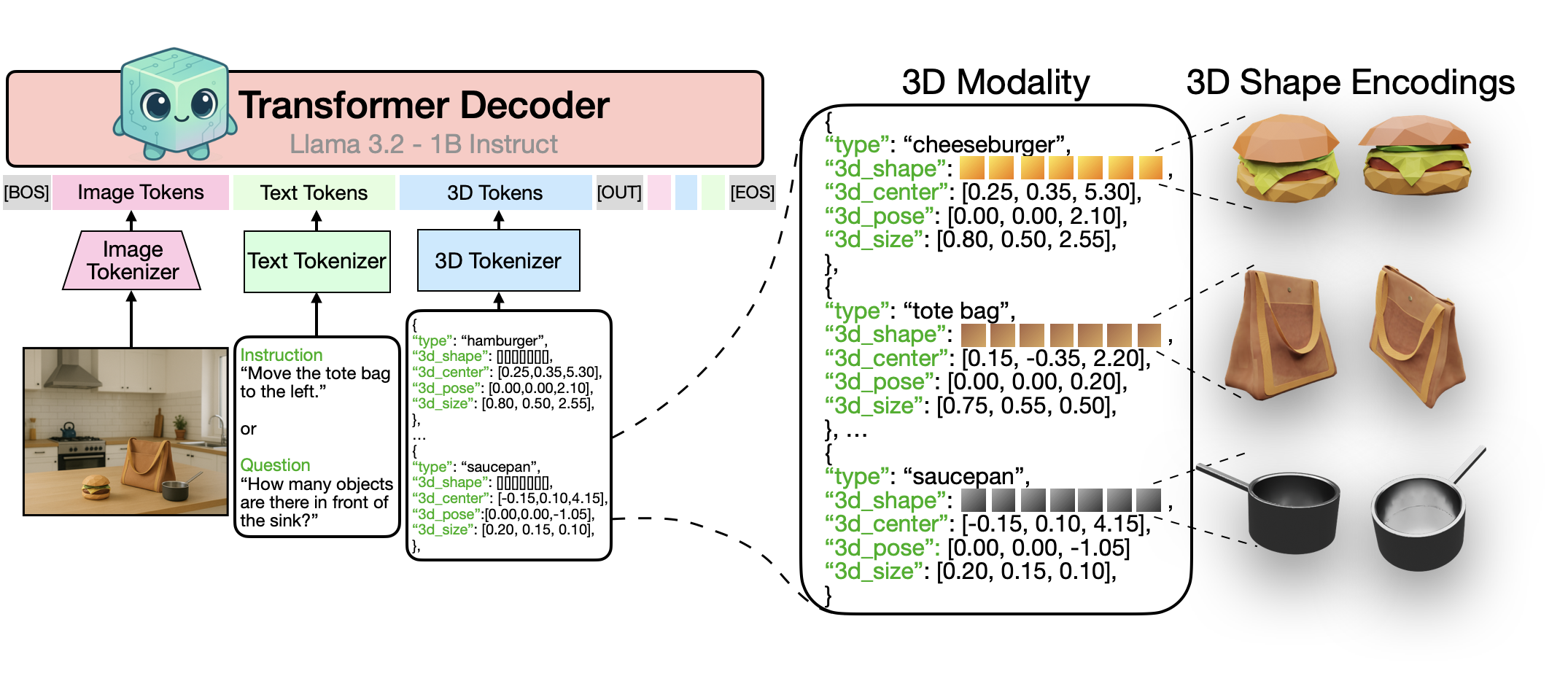
We present a unified LLM that aligns language, images, and structured 3D scenes, demonstrating
applications in rendering, recognition, instruction following, and 3D QA.
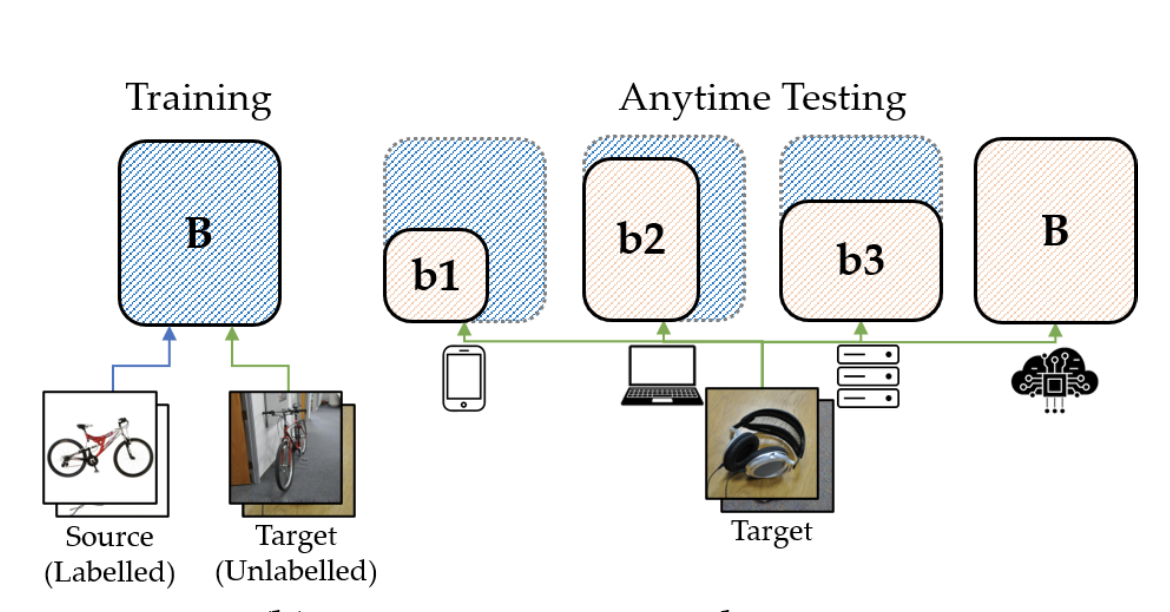
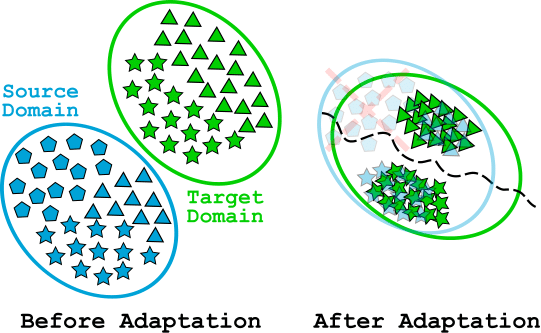
We propose a domain-alignment approach with switchable depth, width, and input resolution to realize
accuracy–efficiency trade-offs under different constraints.
Aadarsh Sahoo, Rutav Shah, Rameswar Panda, Kate Saenko, Abir Das —
NeurIPS, 2021
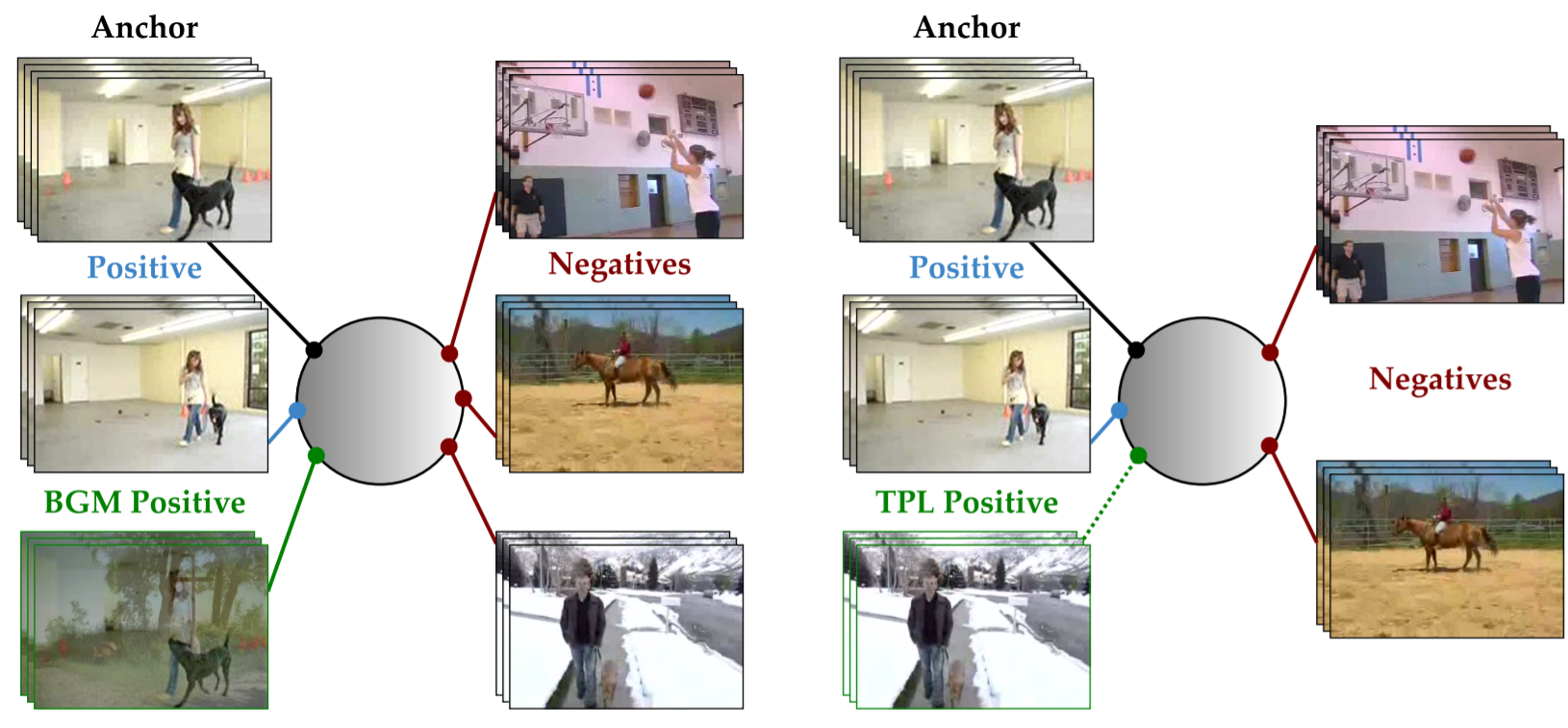
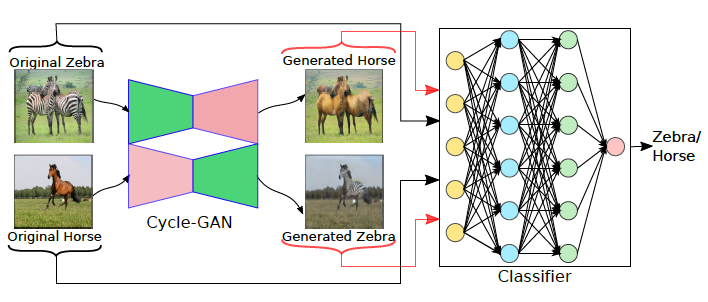
We introduce a temporal contrastive learning approach for unsupervised video domain adaptation by
leveraging video speed, background mixing, and target pseudo-labels.
Aadarsh Sahoo, Rameswar Panda, Rogerio Feris, Kate Saenko, Abir Das —
NeurIPS-W 2021; WACV 2023 (Best Paper Honorable Mention)
We develop a ‘Select, Label, and Mix’ (SLM) framework that aims to learn discriminative invariant feature
representations for partial domain adaptation.


{kind=link}